原文地址 https://docs.google.com/Doc?id=dfqptrrs_0d2f75sf9, 因国内很多地方已不能访问google doc, 所以转贴之。原文如下:
前情
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
6月18日央视《焦点访谈》
记者:通过谷歌中国能搜索出来的淫秽色情和低俗信息非常的丰富,不仅有交友、视频、还有文字等等,而且搜索起来非常方便,它还提供了这么一种功能,你只要输入一个词,甚至是一个字它就能给你提供若干种选项,更为夸张的是,即使你输入的这个词并不暧昧,但是它却能给你引导到低俗的内容上,不信我们来看一下:输入一个儿子,它下面缺出现了这样的一些选项“儿子母亲不正当关系”等等十个选项,而且这十个选项可以说都将引导你进入到那些低俗的内容,这样的结果应该说我们谁都没有想到。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
参考用“谷歌搜索低俗引导”

Google的搜索引导词是根据近期搜索频率来分的,也就是说,引导词里会出现最近一段时间内搜索的次数较多的组合。Google Trends上就能查到流量比较大的情况下的搜索频率走势。
而更为先进的Google Insights for Search(http://www.google.com/insights/search/)里则详细地记录下了2004年至今各搜索组合的次数涨落,并且还可细分网页搜索、图片搜索、新闻搜索,和按不同国家与地域、不同时间段来进行检索。
请看图说话。
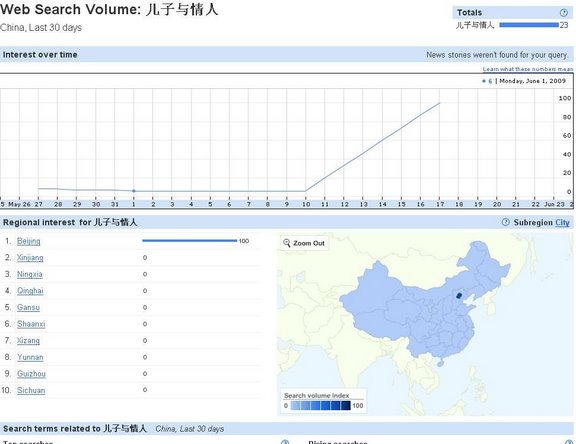
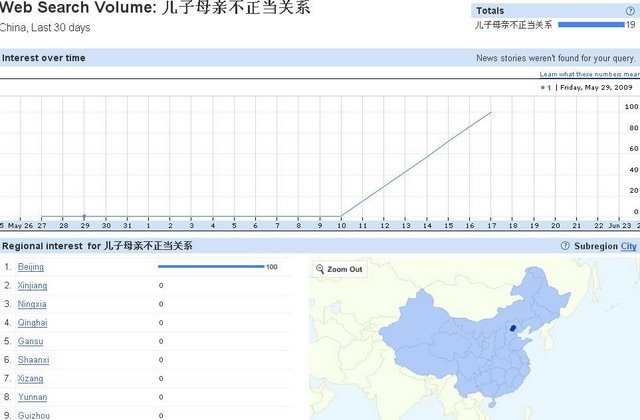

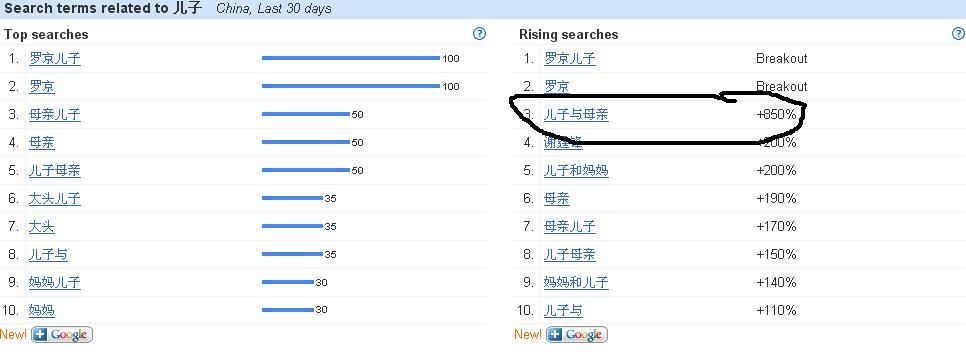
解读:
在这几张“30天内统计数量”的表里我们可以看到,从6月10日起,“儿子与情人”和“儿子母亲不正当关系”两种搜索组合的搜索率直线上升,而之前的搜索量则几乎可以忽略不计。并且这些搜索近100%都是由北京的用户完成的。而且这些词条总共也就被搜索了十几二十来次。
同样,在搜索频率上升排行中我们也可以得到印证,这两个条目在过去从来没有这么“火热”过。
巧合?
同样是6月10日,同样是北京用户。同样是20次上下的搜索次数。
巧合?
真的是巧合吗?
_________________________________________________-
答疑:
有人问:数据图怎么都一样的?
仔细看,除了6月10日到6月18日的上升趋势惊人一致外,其他是有区别的。
比如第一图6月1日、第二图5月29日、三四图的上升量、五图的5月29与30日之间等等。









